Speechsynthesis & Google TTS
프로젝트 진행하며 경험해본 Speechsynthesis & Google TTS
2022-01-22
이번에 유지보수하면서 진행했던 TTS (Text-to-Speech)
단어의 발음을 읽어주도록 해야했다.
결국 Google TTS로 구현하긴 했지만, 처음에는 Speechsynthesis를 사용해 구현했었다.
Sppechsynthesis는 (음성 합성) Web Speech API이고 주어진 텍스트를 소리로 바꿔주는, 음성 서비스에 대한 컨트롤러 인터페이스이다.
Speechsynthesis
IE빼고 브라우저 거의 지원한다.
speechSynthesis.getVoices();
로 지원하는 음성 목록을 확인할 수 있다.
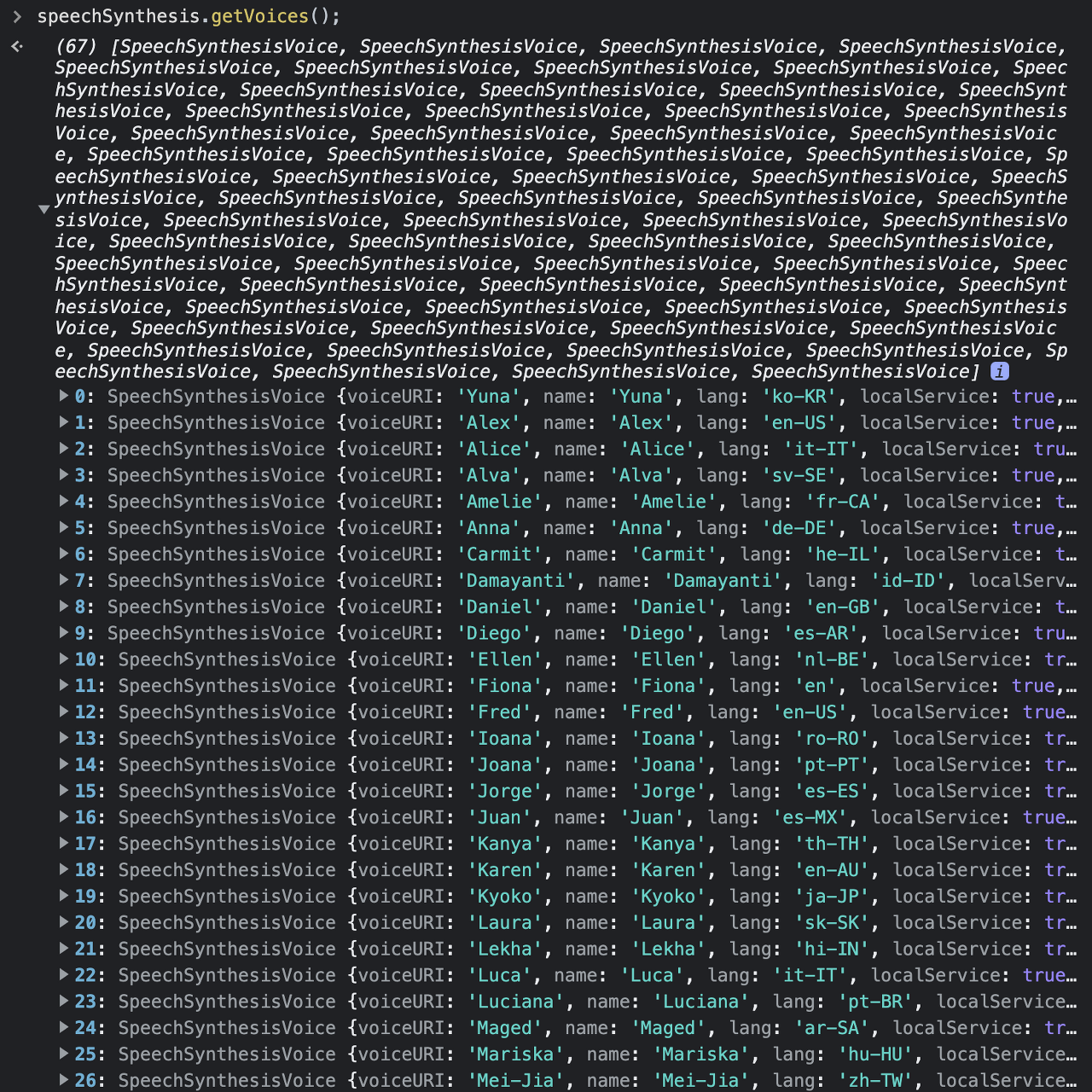
문제는,, 브라우저마다 또는 OS마다 지원하는 음성이 달라서 모두 동일하지 못했다,
그래서 모바일따로 웹따로 브라우저별로 목소리가 다르게 세팅되어 Google TTS로 바꾸게 되었다.
const speech = new SpeechSynthesisUtterance()
// 음높이와 목소리 등 설정이 가능
speech.voice
speech.text
speech.lang
speech.pitch
speech.rate
speech.volume
// speechSynthesisUtterance에 설정한 음성 실행
window.speechSynthesis.speak(speech)
Google TTS
두가지 방식이 있었다.
클라이언트 라이브러리와 API
클라이언트 라이브러리
Node.js
npm install --save @google-cloud/text-to-speech //라이브러리 설치
// Imports the Google Cloud client library
const textToSpeech = require('@google-cloud/text-to-speech');
// Import other required libraries
const fs = require('fs');
const util = require('util');
// Creates a client
const client = new textToSpeech.TextToSpeechClient();
async function quickStart() {
// The text to synthesize
const text = 'hello, world!';
// Construct the request
const request = {
input: {text: text},
// Select the language and SSML voice gender (optional)
voice: {languageCode: 'en-US', ssmlGender: 'NEUTRAL'},
// select the type of audio encoding
audioConfig: {audioEncoding: 'MP3'},
};
// Performs the text-to-speech request
const [response] = await client.synthesizeSpeech(request);
// Write the binary audio content to a local file
const writeFile = util.promisify(fs.writeFile);
await writeFile('output.mp3', response.audioContent, 'binary');
console.log('Audio content written to file: output.mp3');
}
quickStart();
구글의 샘플코드
위 코드로 테스트해보니 output.mp3 파일이 만들어지고 이 파일을 재생하면 요청한 text가 재생됐다.
하지만 파일도 필요없고, 음성만 클라이언트에서 받으면 됐기 때문에 조금 더 살펴봤는데, reponse 부분에서 arrayBuffer의 버퍼데이터가 찍혔고, 이 response 데이터를 바로 클라이언트로 보내줬다.
React
const requestAudioFile = async (e) => {
const audioContext = new (window.AudioContext || window.webkitAudioContext)
const response = await axios({
method: 'get',
url: `http://localhost:4000/exam1`,
params: {test: e.target.ariaValueText},
responseType: 'arraybuffer'
})
// 버퍼 데이터 비동기 디코딩
const audioBuffer = await audioContext.decodeAudioData(response.data)
// 오디오 source 만들기
const gainNode = audioContext.createGain()
const source = audioContext.createBufferSource()
// 생성된 source에 재생할 데이터 선언
source.buffer = audioBuffer
source.connect(gainNode)
// 재생할 스피커에 source 넣기
gainNode.connect(audioContext.destination)
source.start()
console.log('responce', response.data);
console.log('audioContext', audioContext);
// -------------- //
const audioBuffer = await audioContext.decodeAudioData(decode);
console.log('audioBuffer', audioBuffer);
//create audio source
const gainNode = audioContext.createGain()
const source = audioContext.createBufferSource()
console.log('source : ', source);
source.buffer = audioBuffer
source.connect(gainNode)
gainNode.connect(audioContext.destination)
source.start();
}
읽혀야할 text를 params로 보냈고, Web Audio API 의 AudioContext를 사용해서 받아온 버퍼데이터를 읽도록 했다.
근데 몇가지 문제가 더 있었는데, 모바일에서는 작동하지 않는것..audio 태그를 이용해 읽혀야 하기 때문에 버튼 커스텀이 되지 않았다.
그래서 변경한게 API
POST https://texttospeech.googleapis.com/v1/text:synthesize?key='Google API KEY'
{
"input":{
"text":"Android is a mobile operating system developed by Google, based on the Linux kernel and designed primarily for touchscreen mobile devices such as smartphones and tablets."
},
"voice":{
"languageCode":"en-gb",
"name":"en-GB-Standard-A",
"ssmlGender":"FEMALE"
},
"audioConfig":{
"audioEncoding":"MP3"
}
}
위처럼 작성해 POST요청을 보내면
//NExAARqoIIAAhEuWAAAGNmBGMY4EBcxvABAXBPmPIAF//yAuh9Tn5CEap3/o
...
VVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVVV
음성이 base64 인코딩 형식으로 들어온다.
받은 인코딩된 음성을
const [audioSource, setAudioSource] = useState(null)
const requestAudioFile = async (e) => {
const response = await axios.post(
// eslint-disable-next-line no-undef
`https://texttospeech.googleapis.com/v1/text:synthesize?key=${process.env.REACT_APP_GOOGLE_TTL}`,
{
input: {
text: e?.target?.ariaValueText
},
voice: {
languageCode: 'en-US',
name: 'en-US-Standard-H',
ssmlGender: 'FEMALE'
},
audioConfig: {
audioEncoding: 'LINEAR16',
speakingRate: 1
}
}
);
setAudioSource(new Audio("data:audio/wav;base64," + response.data?.audioContent));
};
useEffect(() => {
audioSource?.play()
}, [audioSource])
new Audio 오디오 객체를 이용해 오디오소스가 들어올때, 오디오를 만들고 재생시켰다.